Голосовой ИИ научился слышать настроение собеседника и менять тон в ответ
Голосовой ИИ научился слышать настроение собеседника и менять тон в ответ
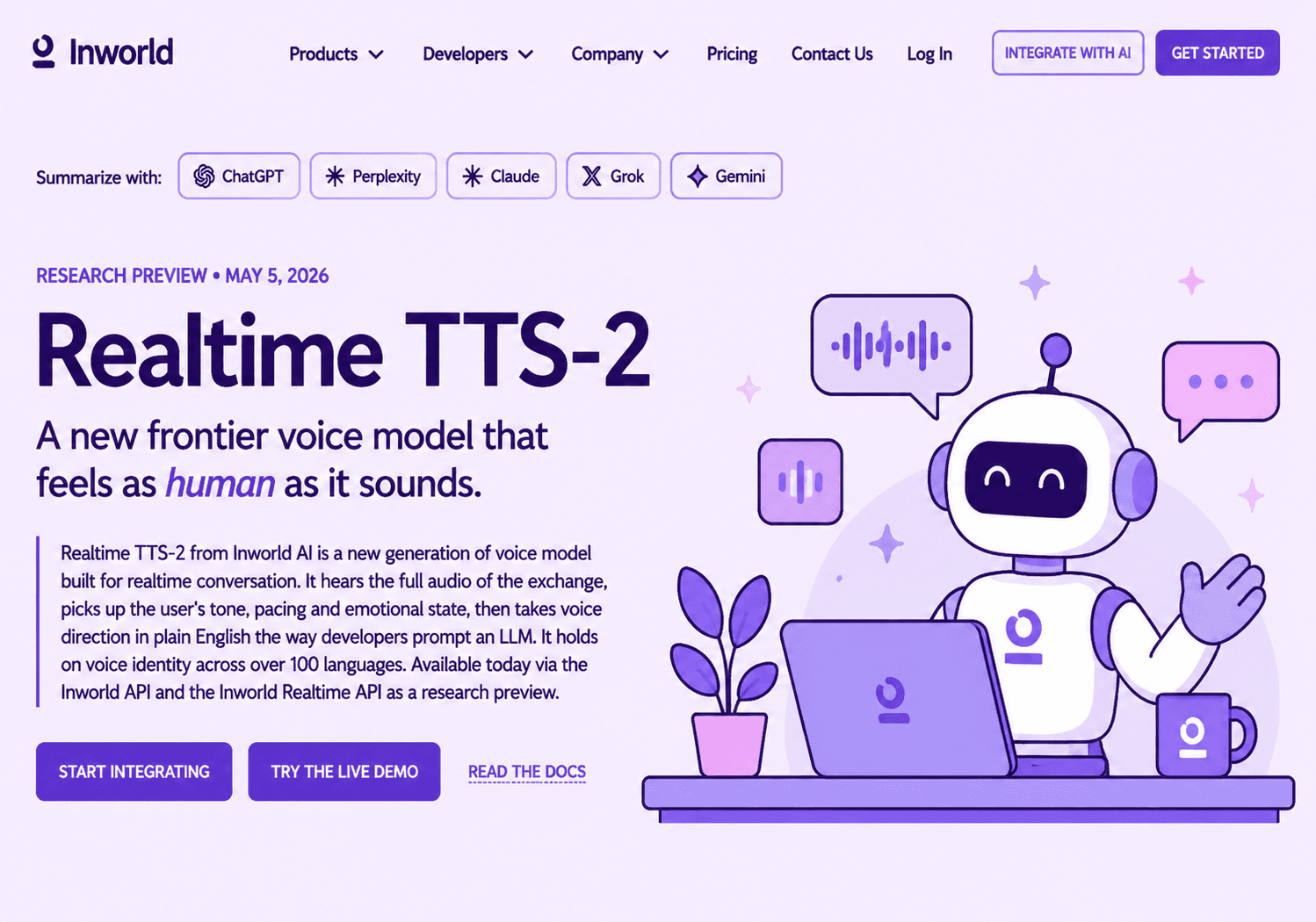
Inworld AI выпустила Realtime TTS-2 (https://inworld.ai/blog/realtime-tts-2) — голосовую модель для живых разговоров в реальном времени. Главное отличие, модель слушает реальное аудио из предыдущих реплик диалога. Она слышит, как звучит пользователь, определяет его тон и эмоциональное состояние, и подстраивает свой ответ под этот контекст. Одна и та же фраза прозвучит мягче после плохих новостей и живее после шутки.
Голосом можно управлять через обычный текст, как режиссёр актёром: пишешь описание нужной подачи, модель именно так и говорит. Поддерживается больше 100 языков, при переключении между ними голос остаётся одним и тем же человеком. Внутри текста можно расставлять метки [вздох], [смех], [пауза], и модель добавит их как естественные звуки, а не произнесёт как слова.
До этого голосовые модели обучались на аудиокнигах и нарративном чтении, тексте в одну сторону, без реакции на собеседника. TTS-2 строилась изначально под двустороннее общение. По независимому рейтингу Artificial Analysis Speech Arena модель занимает первое место среди всех TTS-систем, обгоняя Google и ElevenLabs.
Доступна через Inworld API, задержка до первого аудиочанка менее 200 мс.
Подпишись,
чтобы
ничего не
пропустить
Ежедневные подборки промптов, свежие новости и материалы об ИИ — там, где удобно. Без спама, только редакционный отбор.