Вышла модель с контекстным окном в 12 миллионов токенов в пять раз дешевле GPT и Claude
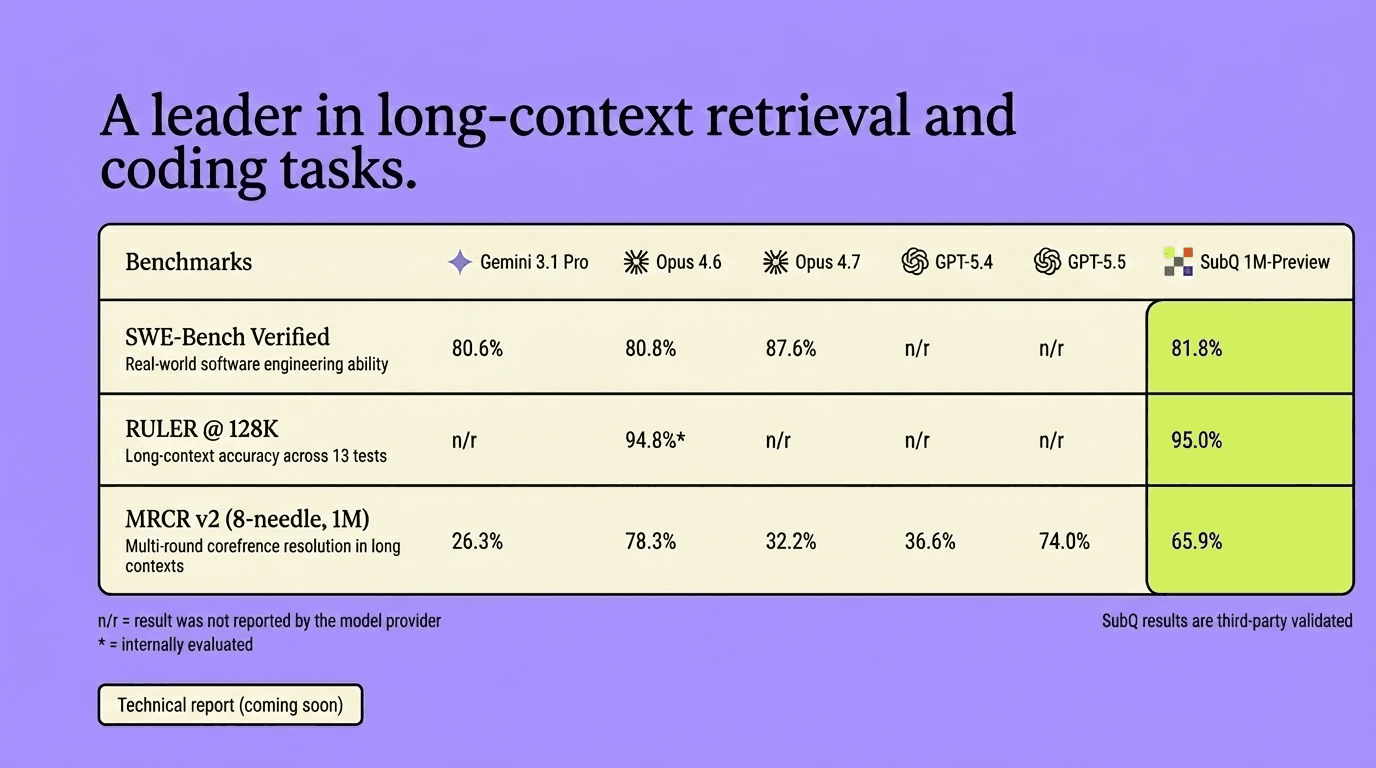
Стартап Subquadratic выпустил языковую модель SubQ с рекордным контекстным окном в 12 миллионов токенов. Для сравнения: большинство топовых моделей в 2026 году останавливаются на 1 миллионе.
12 миллионов токенов — это примерно 9 миллионов слов или около 120 книг в одном запросе. В основе архитектура разреженного внимания: стандартные модели сравнивают каждый токен с каждым другим, что с ростом контекста требует всё больше вычислений. SubQ выбирает только значимые связи и игнорирует остальные. По заявлению разработчиков, на контексте в 12 миллионов токенов это снижает вычислительную нагрузку почти в тысячу раз.
Стоимость обработки в пять раз ниже, чем у Claude Opus или GPT-5.5 при сопоставимых задачах. Если цифры подтвердятся независимыми тестами, необходимость в RAG-пайплайнах и векторных базах данных для многих задач существенно снизится, весь документ можно просто подать в контекст целиком.
Скептики указывают на отсутствие открытой архитектуры и независимых бенчмарков. Пока модель доступна только через ранний доступ по API на сайте (https://subq.ai/).
Подпишись,
чтобы
ничего не
пропустить
Ежедневные подборки промптов, свежие новости и материалы об ИИ — там, где удобно. Без спама, только редакционный отбор.